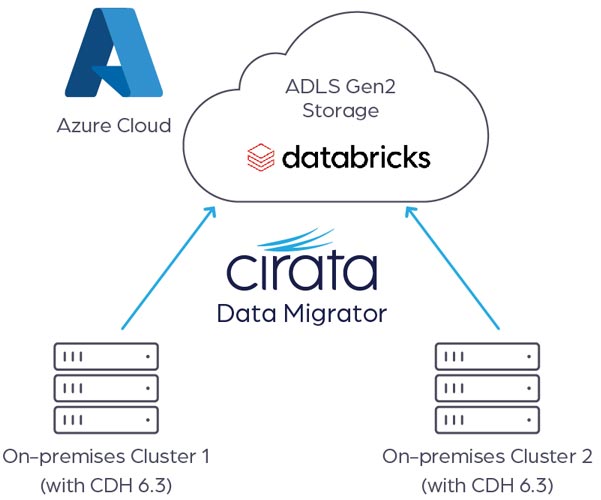
Following a proof-of-concept (PoC) the organization selected Cirata for their on-premises data lake to Azure cloud data transfer process. Data Migrator is an automated, scalable, high performance, and cloud-agnostic data integration solution that simplifies making data available in and immediately usable across on-premises environments and with any cloud platform. The PoC demonstrated that Data Migrator would meet all of their requirements and address their data transfer challenges.
The organization also evaluated alternative solutions such as DistCp (distributed copy) and AZCopy (Microsoft Azure’s DistCp based technology). They indicated that they were not able to reach their throughput requirements with AZCopy, and similarly saw a “performance lag” with DistCp. Furthermore, DistCp and AZCopy are designed to copy data based on a single point in time. Any data ingested or changed since the copy process started would not be picked up, and subsequent scans are needed to capture ongoing data changes. To prevent this from happening requires the production system to be brought down, which was unacceptable.
Data Migrator performs the initial data transfer using a single scan of the source storage, while also supporting continuous replication of any ongoing changes from source to target with zero disruption to current production systems.
Data Migrator is installed on an edge node of the source cluster, and deployment can be performed in minutes and does not require any custom coding or changes to source applications. The organization was able to easily configure data transfer jobs to meet their specific requirements, such as data sets to transfer, exclusion rules, bandwidth management and more. Verification capabilities ensure all data is transferred, and the product user interface allows for management and to monitor the full data transfer process from a single console.